Instroducing Lightning-4b
In recent years, the use of LLMs has been increasing in the field of data analysis. Because demand for data analysis is centered on analyzing customer and financial data, many analytical AI SaaS services rely on major providers like OpenAI, despite significant privacy concerns. This is because the nature of data analysis tasks requires LLMs to have the ability to invoke complex tools and a wide context window for handling table data and analytical code.
We first attempted to design an efficient context. Many LLM-based analytics rely on Python tool execution. But storing execution results consumes a huge number of tokens. To reduce this cost, we designed a new XML-based output format.
Output Format:
<python>
import pandas as pd
import matplotlib.pyplot as plt
df_material_type = pd.read_sql_query("SELECT material_id, material_type FROM material", con=engine)
...
</python>
<report>
## Analysis Procedure
1. Extracted material_id and material_type from the material table.
2. Verified data presence and obtained {df_material_type.shape[0]} rows.
...
## Analysis Results
Number of materials per material_type
{df_type_count}
Figure:
{fig}
</report>Instead of waiting for code execution to complete, the model generates a report immediately, embedding variables into placeholders ({}). This approach isn’t ideal for high-level exploration or strategic insights, but it works extremely well for joins, aggregations, and visualizations. Most importantly, required tokens no longer scale with dataset size—removing the need for high-end GPUs to run analysis locally.
Early Challenges
Designing reports that gracefully handle unexpected errors proved tricky. Smaller models also struggled: they tended to hallucinate variables, inject raw Python into reports, or endlessly “overthink” instead of producing results. When testing with Qwen3-32B, even after we tried hard to adjusting the system prompts, we still observed problem such as hallucination, where variables were fabricated without being embedded, and overthinking, where the model continued to think endlessly.
We then attempted to train the model using SFT (supervised learning) on exemplary output examples. Models with parameters of 20 or more, such as Devstral, produced sufficiently stable results, but smaller models like Qwen3-4B continued to hallucinate or embed files directly in reports.
Next, we tried GRPO (Group Relative Policy Optimization), which worked well. Before training, qwen3-4b couldn't even correctly output XML format, but now it achieves accuracy on par with other SOTA models!
Training Setup
We trained using unsloth and Lambda Labs H100 GPUs, inside a Docker environment with:
- A Python sandbox
- Sample databases
- An execution engine for parsing outputs and embedding variables into reports
Training queries (approximately 2k in total) were based on open-source datasets and common statistical/relational operations.
Designing the reward function required extensive trial and error, but eventually settled on the following:
- Correctness of XML formatting
- Absence of Python runtime errors
- Overall quality of the report (placeholders, relevance to the query, etc.)
- Quality of reasoning (ability to surface issues and propose fixes)
- Python code design (error handling, robustness)
The last three were judged via LLM-as-a-judge. Importantly, models were rewarded even when analysis failed—so long as the report surfaced error causes and partial progress clearly.
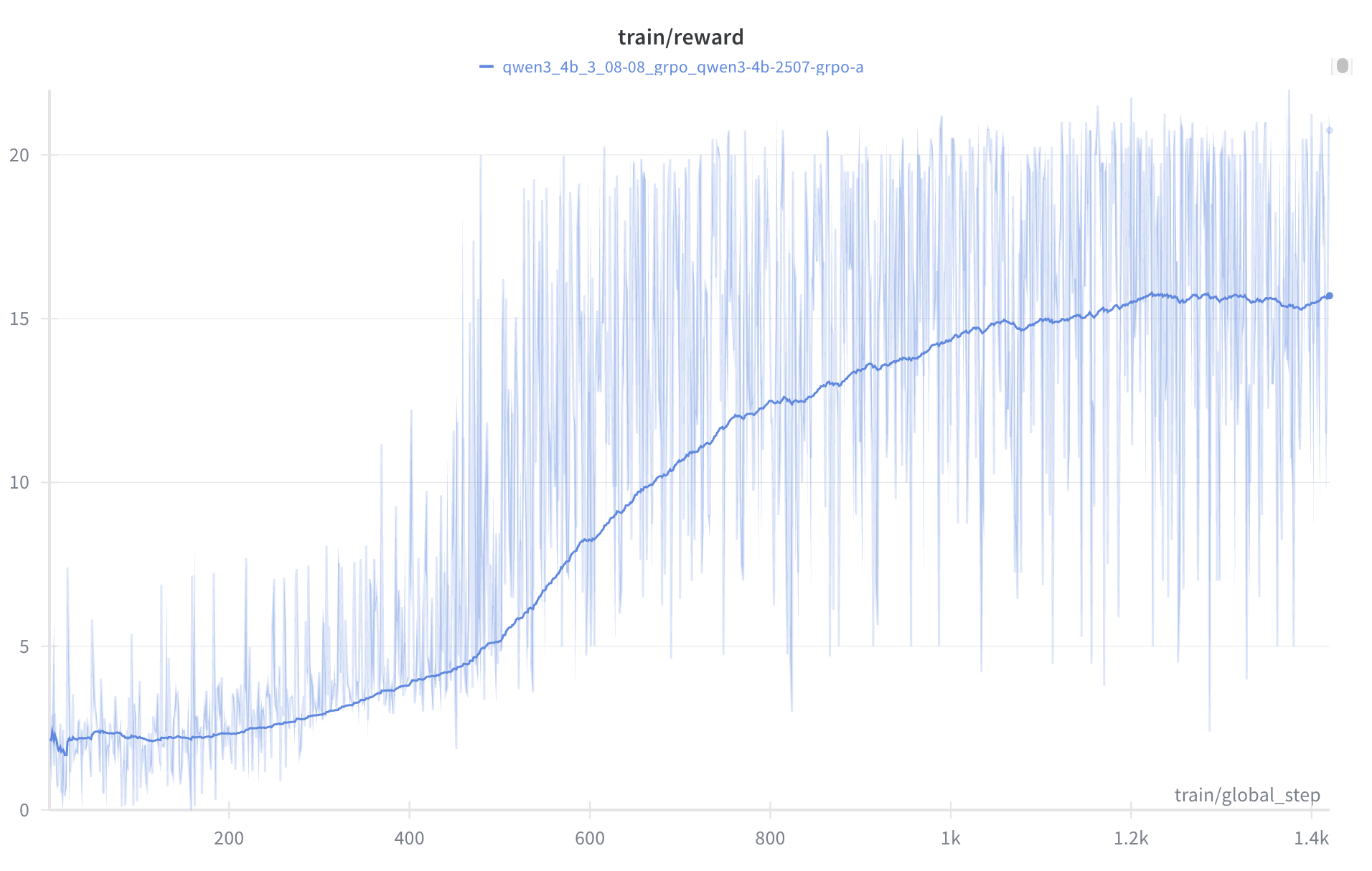
We also tried curriculum learning and pre-SFT, but no significant improvement was observed. We also trained a smaller model (qwen3-1.7) using the same training setup. Improvements were observed as well as 4b model, but not to a practical level. Due to GPU funding issues, we were unable to test models larger than 4B. (GRPO requires more VRAM than expected!)
Results
When we trained Qwen3-4B-Thinking-2507, the impact was obvious from the first evaluation: It always generated the correct format, and any error messages captured by try/catch were embedded in the report. While no specific penalty was set for the length of the thought process, the thought process was simplified, and the Python code was streamlined by eliminating unnecessary lines such as print. We evaluated the model using a separate sample database prepared for validation and 122 analytical queries. We found that it outperformed a model with 50 times the parameters.

The takeaway: SFT is great for injecting knowledge, but GRPO is the key to shaping model “habits.” With the right environment and reward design, we can correct formatting, enforce error handling, and shape code-writing behavior at the weight level.
Total training time (excluding trial-and-error) was about 72 hours on a single H100 GPU.
Try It on quelmap
You can download the model here:
👉 Hugging Face: https://huggingface.co/quelmap/Lightning-4b
To run data analysis with it, use quelmap—an open-source tool that provides all the necessary functionality: data upload, a built-in sandbox, and variable substitution. It runs entirely locally, making it ideal for handling sensitive data. Even on a MacBook Air M4 with 16GB of memory, performance is smooth.
👉 GitHub: https://github.com/quelmap-inc/quelmap
👉 QuickStart: https://quelmap.com/quickstart
What’s Next
We’re working on extending this research toward multi-step analysis orchestration, making advanced pipelines possible even in GPU-constrained environments. If you’re excited about democratizing analytics, we’d love to hear from you—let’s collaborate!
For enterprises and research labs, we also develop custom analytics agents tailored for strict privacy requirements. Learn more on our Enterprise page.